Building an app to scale on Laravel Vapor
Running thenping.me reminds me of an old colleague that used to say "billing everybody on the 1st of the month leaves you with compute doing nothing for the rest of it"
Running thenping.me reminds me of an old colleague that used to say "billing everybody on the 1st of the month leaves you with compute doing nothing for the rest of it"
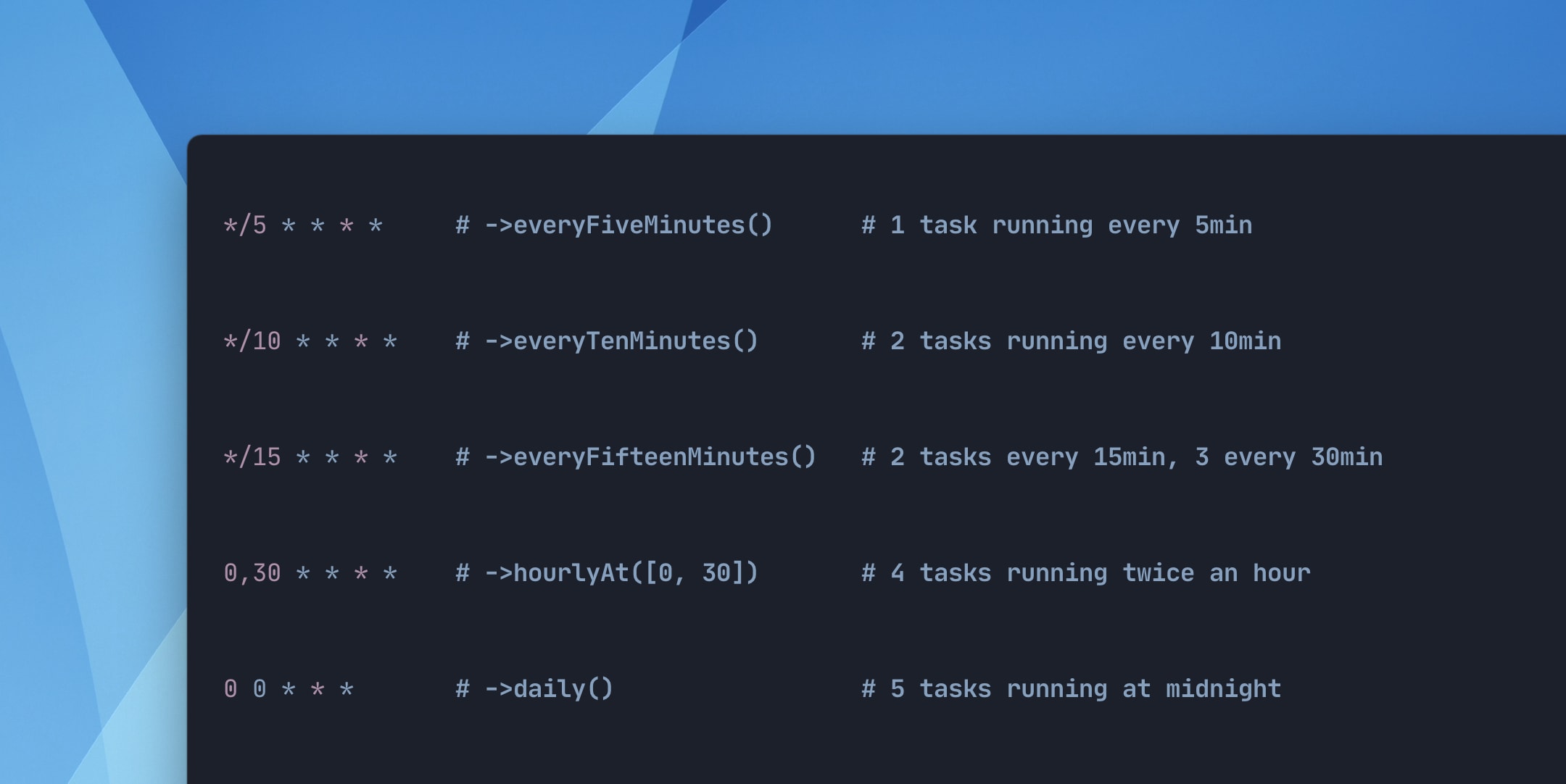
Overlapping tasks
The above illustrates how your application's discrete scheduled tasks will wind up falling on the same start time over a long enough time window.
In your own applications, this is almost never going to be a problem, with exception to a long-running task to overlap itself, or to push subsequent tasks off-schedule. In many cases, you might not even notice.
For example, your task that is scheduled to run every five minutes will fall on the same schedule as a task scheduled to run every ten minutes on every other execution.
How this causes pain
For us, though, overlapping scheduled tasks pose a significant challenge. In a single application, the overlap may be a handful of tasks, but for a platform that is monitoring scheduled tasks for many applications, this can lead to large and sudden influxes of requests.
When you consider the varying schedules, the start of any given hour and at midnight on any given day, scaling to support this influx of traffic has been a challenge.

We were working to account for two things:
- Incorrectly sending notifications to our users because our app was unable to keep up with the load to fulfill our end of the work efficiently and,
- Stop the regularly influx of error notifications into Slack
Vapor to the rescue?
Fortunately, we're hosted on Laravel Vapor, which promises on-demand auto-scaling with zero server maintenance. What this means is that we can theoretically scale to support an infinite number of HTTP requests.
In practice, things are a little more nuanced, and as with many applications, the database becomes the bottleneck.
As thenping.me is still a fledgling service, we're running on modest hardware (a t3.micro), particularly at the database level which is one of the more expensive aspects of our platform.
A t3.micro instance allows us to support ~85 concurrent connections to the database, which is almost always fine, except when everybody's daily reports come flooding in and we're suddenly fielding hundreds of concurrent HTTP requests.
Now we need to figure out whether we grossly over-provision a database server that broadly serves us sufficiently to account for sudden influxes in traffic, or look for another option?
Concurrency
Vapor allows you to configure three different levels of concurrency; HTTP, CLI, and queue.
CLI is not relevant to our ingest client pings, so we'll focus only on HTTP and queue concurrency.
Limiting the amount of concurrent traffic your application can handle at the HTTP layer is important as a cost-saving measure, and in support of mitigating Denial of Service attack, but as we're monitoring client applications, we need to make sure that we can respond to their pings as quickly as possible, to avoid the cascading effect of delayed processing and false alerting.
Ideally we want to always be able to scale up at the HTTP layer to ingest pings as quickly as possible, balancing cost and speed of processing, against timely reporting.
The queue is where we process our users' data to ensure tasks are running when they should and alert if not. This needs to happen within a short window - 60 seconds being the smallest interval we support - allowing for any grace period and consecutive failure thresholds.
Importantly, it can't take longer to process the incoming data than the smallest window of failure - two minutes.
Database resources are finite
So whilst we can limit concurrency of our queue workers and HTTP requests, we still need to be able to accept all of the HTTP requests and process those payloads in a short window of time. We also can't afford to drop any of those requests, lest we send the dreaded false alert.
As mentioned earlier, our current database instance can support ~85 concurrent connections shared between HTTP ingest and queue workers.
The trouble is, we're talking database tables in the order of millions of records being queried over and over for customers to find a project identifier, ensure we have a valid payload, that we know about the task we're being pinged for, and that - importantly for us as a business - the user has an active subscription.
Millions of records isn't a lot in the scheme of things, and whilst the queries are relatively quick, the overhead of querying the database from a controller, waiting for a response, deciding what to do with the data (possibly querying the database again), then dispatching a job to the queue to be dealt with can be slow. And you need to be ready for the influxes, which can be held up by flooding concurrent connections.
A more scalable solution
Whilst we can expect high influxes of traffic, the data we need to query for is fortunately rather static.
- How often are you adding new scheduled tasks?
- How often are you changing an existing task's schedule?
- How often are you removing scheduled tasks?
Because tasks, the projects they belong to, and the subscriptions that they're all monitored under are reasonably static, it makes them a very good candidate for caching.
We have single-digit millisecond performance at any scale available to us via DynamoDB and by caching project, task, and subscription data we can avoid making (relatively) expensive database lookups entirely.
Using Laravel's model observers, we can easily cache new records when they are created, update them when they change, and remove them from the cache when deleted, without worrying about keeping stale data we no longer need.
One final (two-part) problem
For debugging and replay purposes, we keep history of every incoming ping request to thenping.me. This allows us to diagnose and resolve processing corner cases (which we have not seen for many months!) or reprocess missed pings (which we have seen infrequently and should not see at all in future).
This required an insert to the database very early on in the ingest request cycle, which meant we were still seeing database connection bottlenecks after caching the project, task, and subscription data above.
We had, however, previously solved this issue; sort of.
Fairly early on, we were bumping on SQS limitations on project setup and sync payloads in applications that have dozens of scheduled tasks as the structure of each task is quite dense, making the overall request payload quite large.
Chris Fidao over at Chipper CI (who we use for our CI pipeline, by the way) had encountered similar limitations in handling webhooks from their supported Git providers, which we had already implemented to address those issues.
The tl;dr in case you didn't want to read the Chipper article, was to write the JSON payload to storage - S3 in our instance - and replace the request body with the object reference before passing it to the queue, then rehydrating it in the queued job. This keeps our job payloads small, and was key to ensuring we could drop the final database query from our ingest endpoint.
So what's the conclusion?
It's fast and it's scalable. You can see the exact moment we cut across to this cached architecture from the AWS metrics for the ~1.5 days either side of the change.
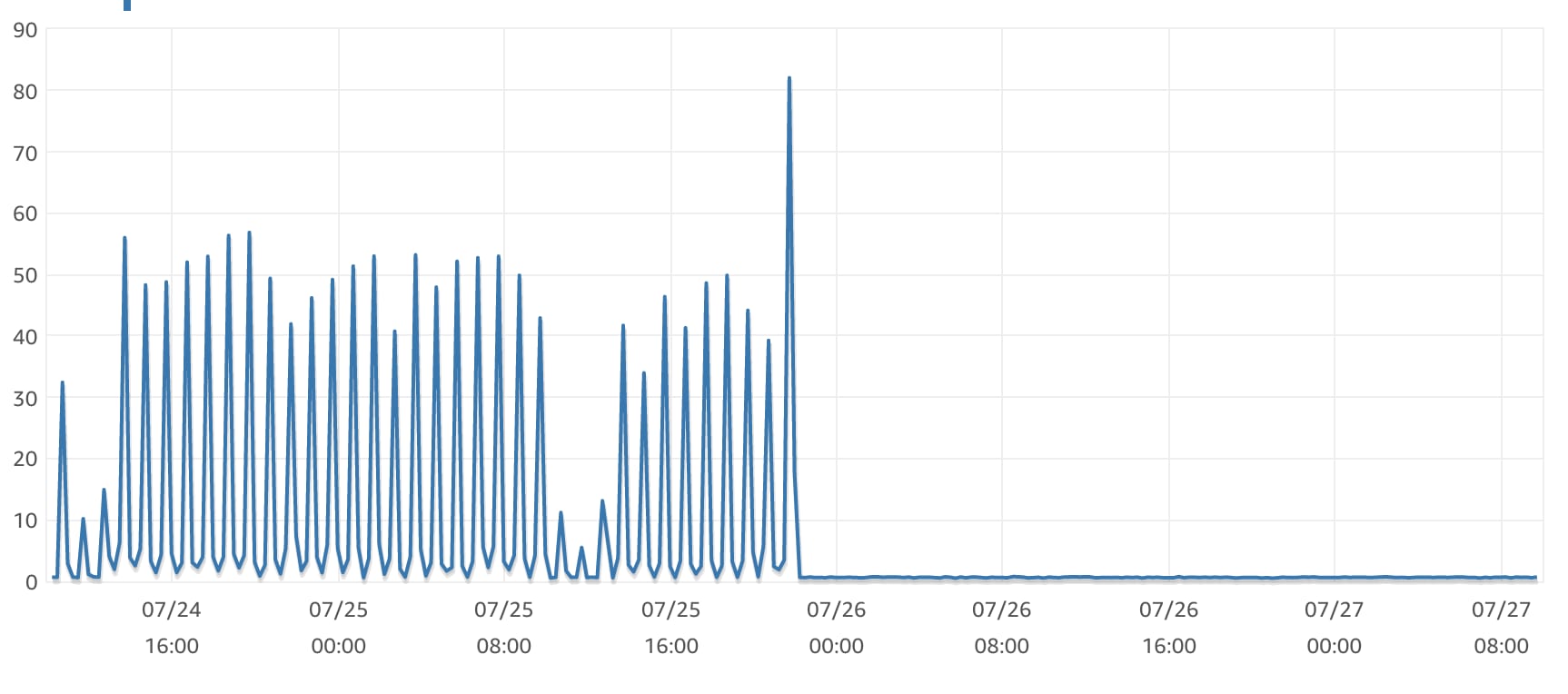
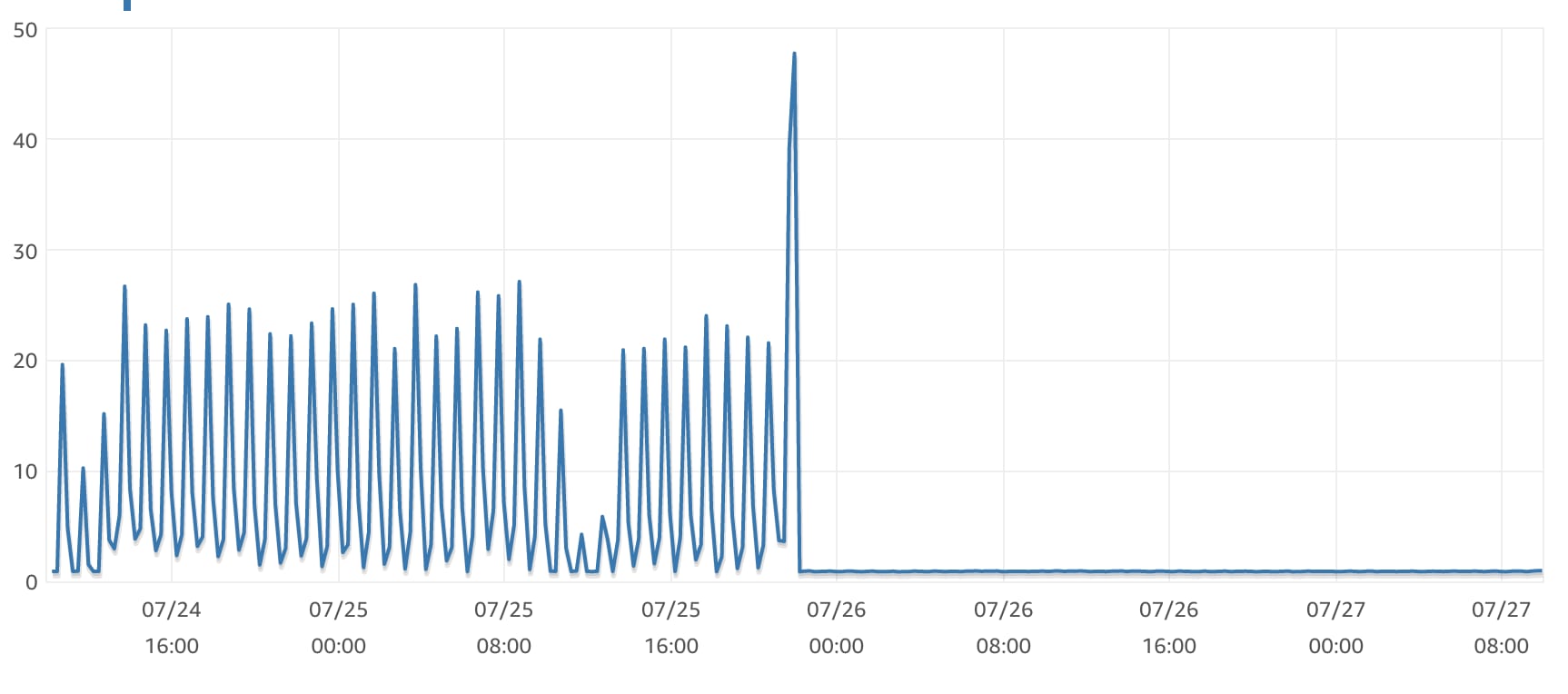
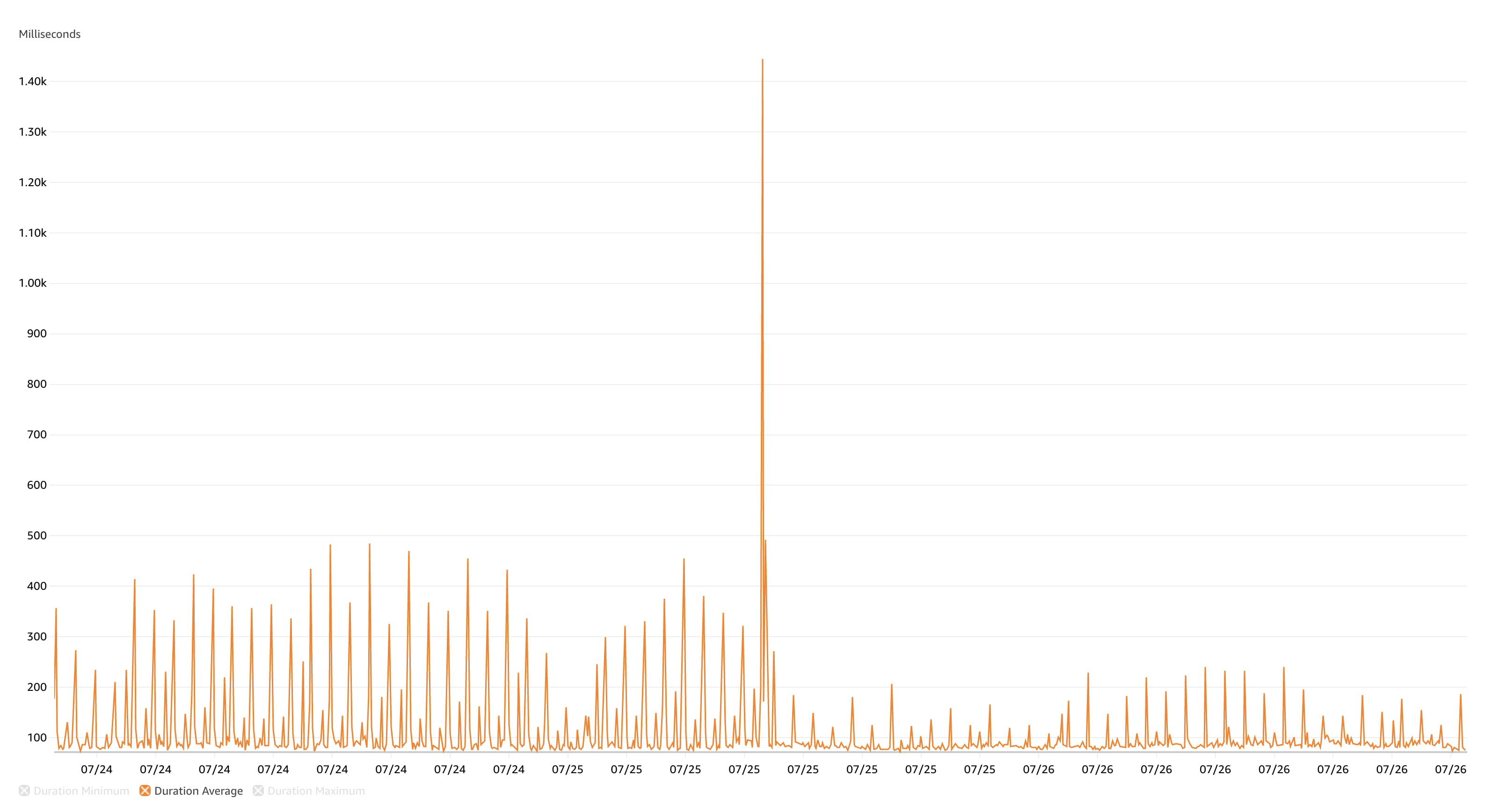
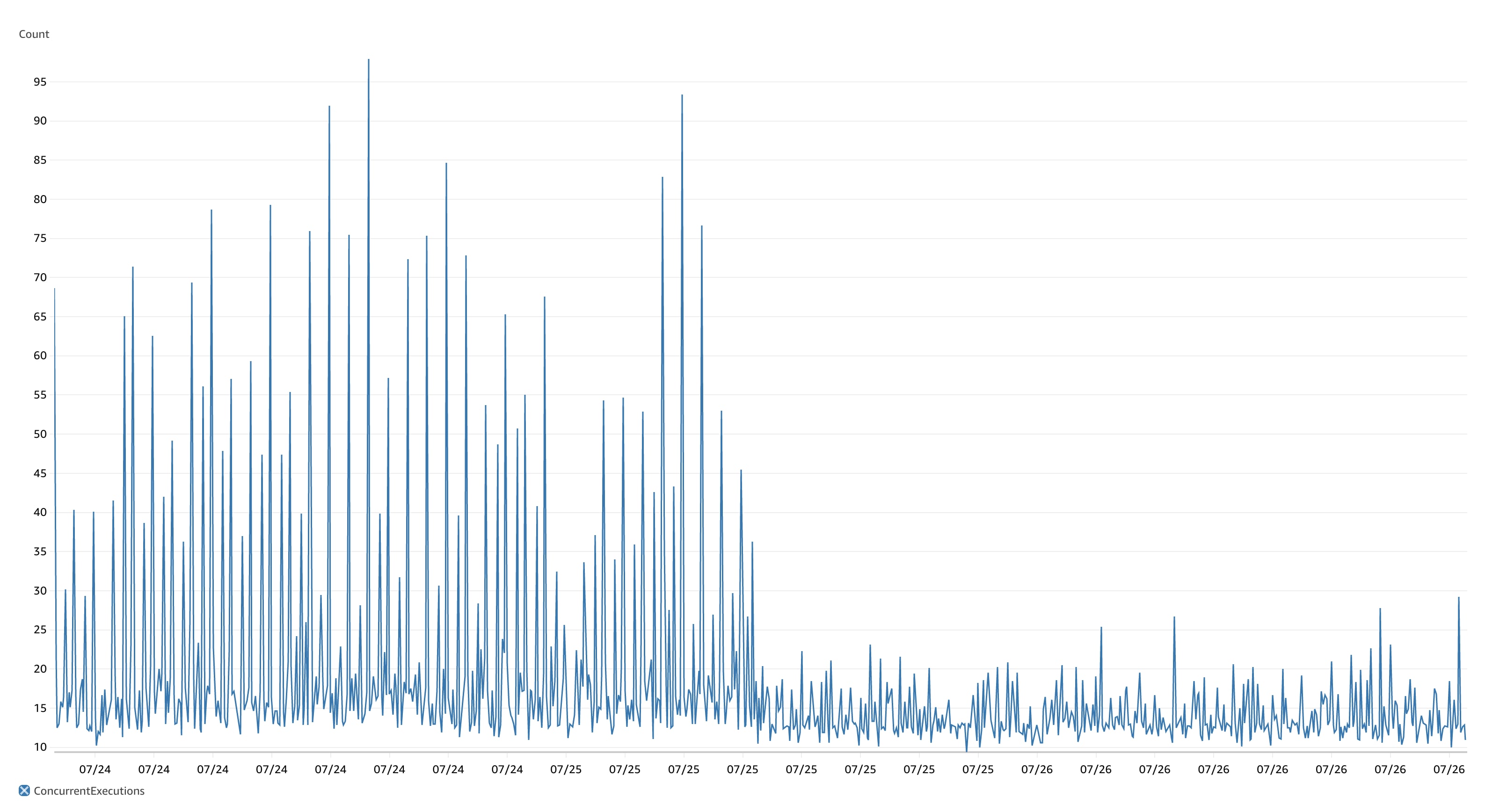
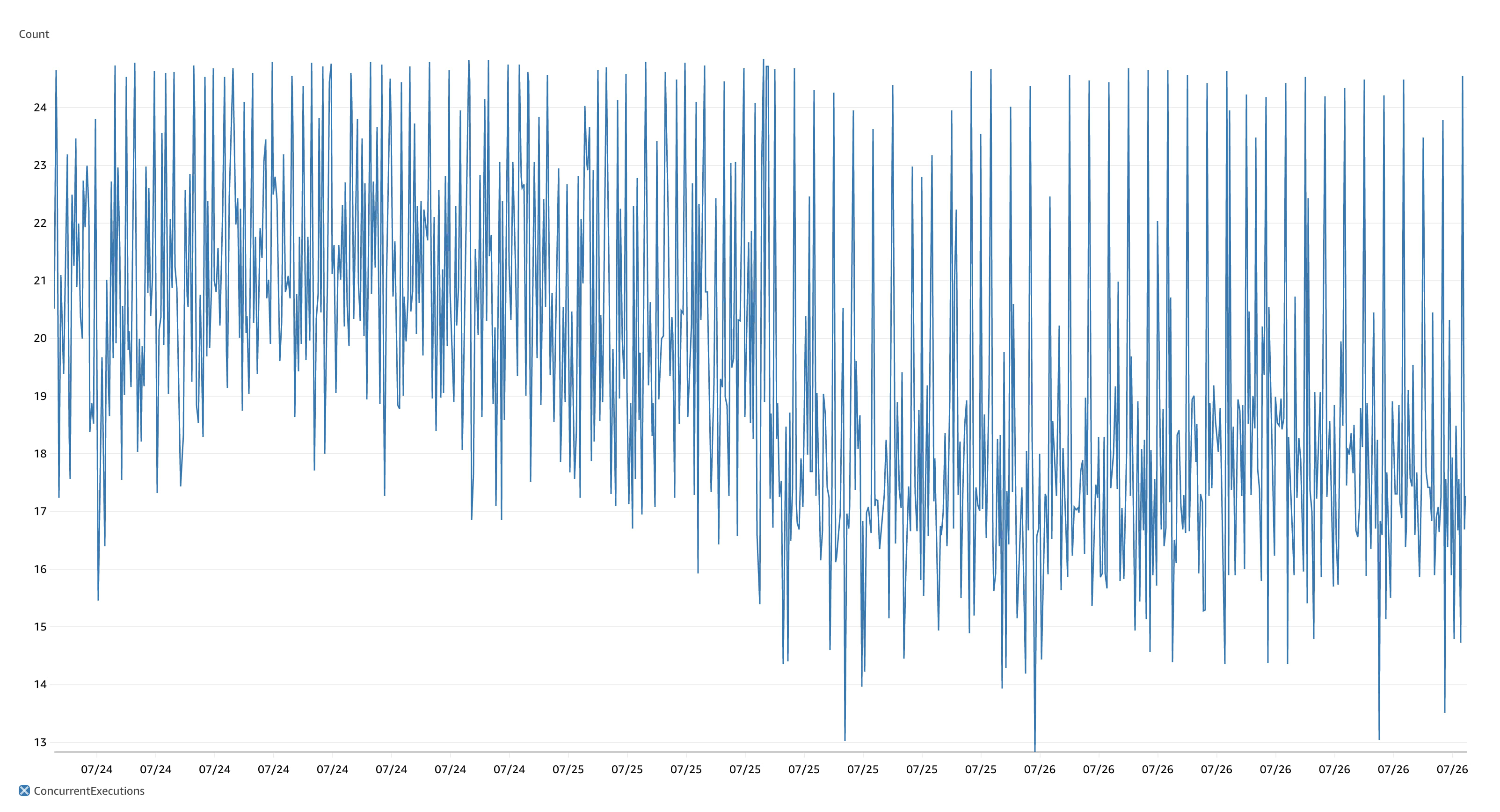
The difference before and after caching was implemented is striking and what blows my mind is how significantly we were able to reduce the number of concurrent HTTP requests with the same workload. The same workload with ~80% less concurrent HTTP invocations and ~75% quicker queue jobs on average. This also translates into HTTP response times some 100ms less than before, whilst our queued jobs are running in less than 100ms.
And because we can do more work with less concurrency, we can continue using our current configuration without increasing our memory or worker requirements for much longer than had we left things as they were.
BUT
We don't know what monetary impact this will have yet.
Pricing is tricky to calculate when it comes to AWS, particularly when you're tying together many pieces of the stack. On Vapor, it's even more tricky as we have a number of variable factors to consider:
- HTTP request invocations, duration, and memory consumption
- Queue invocations, duration, and memory consumption
- DynamoDB reads and writes
- S3 reads and writes
After all this optimisation, the only fixed cost we have left is the RDS instance. This has, however, afforded us the ability to spin up a multi-AZ replica, which should also give us more durability at the database level.
As a result of the optimisations, we've been able to tune down our memory limits across HTTP and queue Lambdas considerably, without impacting throughput, which should help balance the costs as well.
For now, though, we're going to keep an eye on our cost to deliver a fast and highly-scalable service, but it will be interesting to compare the costs month-on-month come September.
Shameless plug(s)
I spoke about scheduled tasks and some of the issues in this post at the Laravel Worldwide Meetup in August 2020 - you can check out the video here.
And if you're interested in learning more about Laravel Vapor, check out Jack Ellis' course Scaling Laravel.
Written by Michael Dyrynda
Principal Engineer, Laravel enthusiast, and open source contributor. I write about web development, PHP, and the problems I solve along the way.